NeurIPS 2025 Spotlight
Yihao Li1, Saeed Salehi2, Lyle Ungar1, Konrad P. Kording1
1University of Pennsylvania 2Technical University of Berlin
Background. Object binding is the ability to group an object’s many features into a coherent whole. Whether Vision Transformers (ViTs) achieve this, and by what mechanism, remains under debate.
What we find. Large pretrained ViTs do perform object binding (though imperfectly). Each patch carries binding information that resides in a shared low-dimensional subspace, and self-attention compares these components pairwise to infer IsSameObject (whether two patches belong to the same object).
Why it matters.
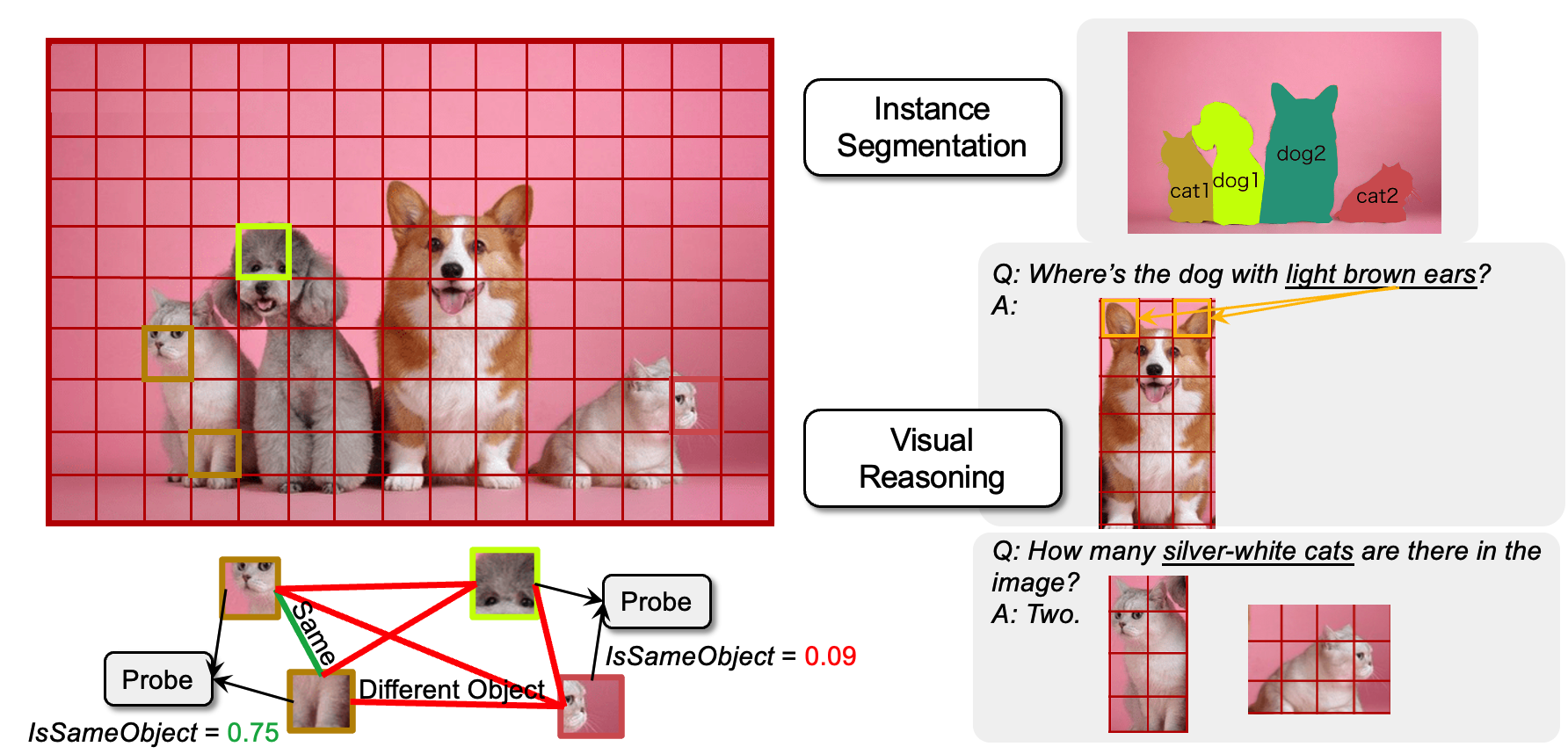
Assessing object binding in ViTs with IsSameObject. Left: We use a probe to decode IsSameObject, a measure of whether two patches belong to the same object, with scores near 1 for same-object pairs and near 0 for different-object pairs. Right: Strong object binding may benefit downstream tasks such as segmentation and visual reasoning (e.g., locating or counting objects with specific features), where patches triggered by certain features must be linked to the rest of their object to extract the whole object.
Binding is an age-old problem in both the design and understanding of intelligent systems. It enables efficient, high-level reasoning and compositional operations over entities or concepts, instead of over low-level perceptual features like pixels.
In this study, we focus specifically on the binding of object parts: how patches (the tokens into which an image is split) belonging to the same object come together to form meaningful groupings that downstream computation can use.
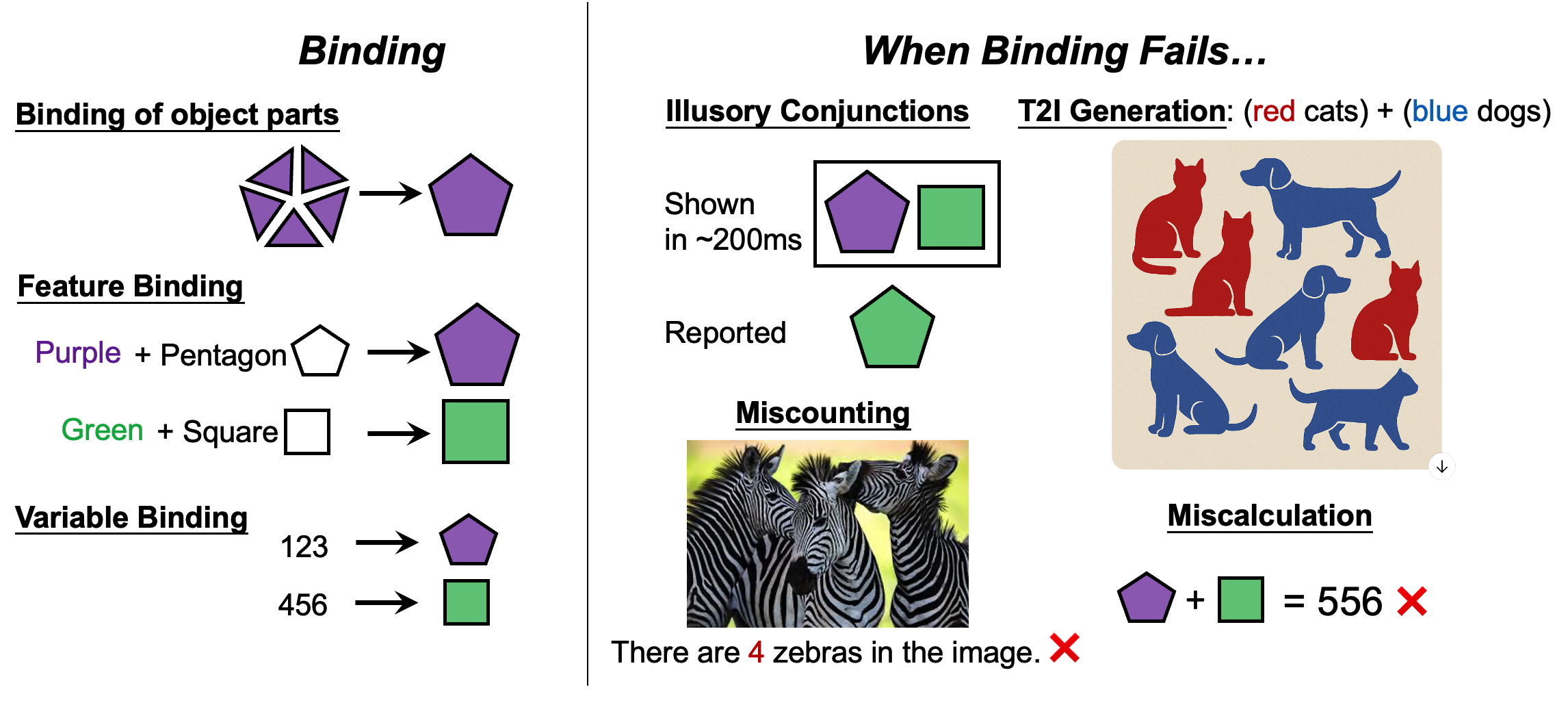
Figure: Binding and its failure modes.
We measure a model's object-binding ability through the decodability of IsSameObject decodability, a value in \([0,1]\) indicating whether two ViT patches belong to the same object. Given patch embeddings \(x_i^{(\ell)}\) and \(x_j^{(\ell)}\) from layer \(\ell\), a probe predicts \( \phi(x_i^{(\ell)}, x_j^{(\ell)}) \in [0,1] \).
We compare several probe architectures to understand how binding information is represented and accessed:
Pairwise probes (1–3) outperform pointwise probes (4): this suggests that binding information is accessed through pairwise operations—e.g., comparing distances in a projected space—rather than through pointwise mappings that assign each patch a discrete label (e.g., “object 3”) and compare those labels.
Quadratic probes (2,3) outperform linear probes (1): this indicates that binding relies on quadratic interactions between patch embeddings, consistent with the quadratic structure of self-attention.
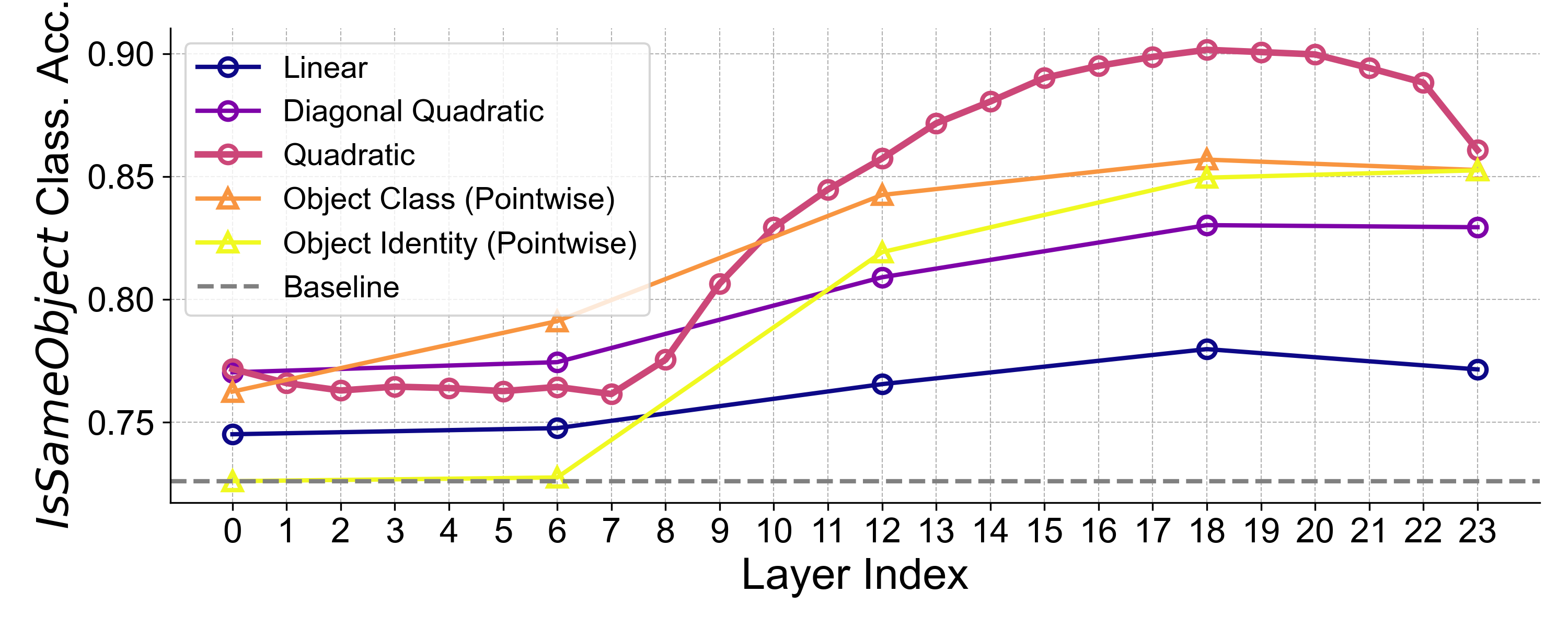
Figure: Layer-wise accuracy of the IsSameObject probe on DINOv2-Large. Quadratic probes excel at decoding the binding signal.
Click any patch on the left image to select it; the right panel then shows the IsSameObject heatmap. Use the layer slider to explore transformer layers, and the arrow buttons to switch images. The demo may take a few seconds to load.
[What does IsSameObject capture beyond attention or feature similarity? It decodes what the model “knows” about which patches belong to the same object, more accurately than attention scores or feature similarity, by using a learned probe that projects activations into a binding subspace. We later show that even visually identical objects can be distinguished, indicating that feature similarity alone cannot explain the binding signal.]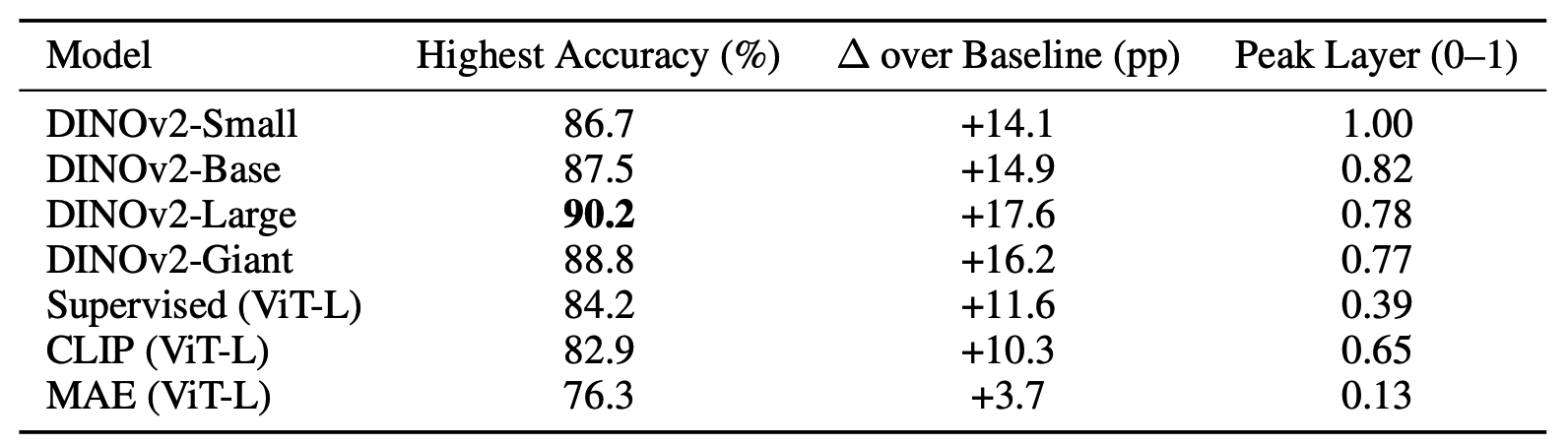
Table: Binding is consistently represented in DINOv2, CLIP and supervised ViT, but less so in MAE.
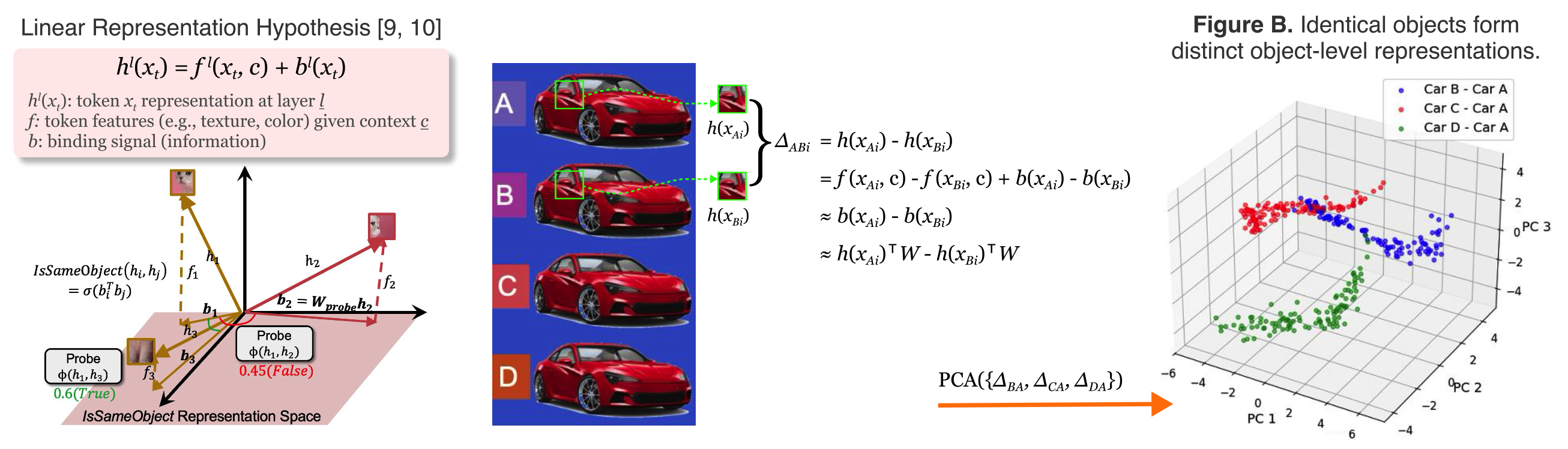
Figure: Identical objects have distinct binding signals. We subtract the embeddings of each car and perform PCA on the resulting differences (ΔBA, ΔCA, ΔDA). The three linearly separable clusters show that visually identical objects yield distinct binding vectors.
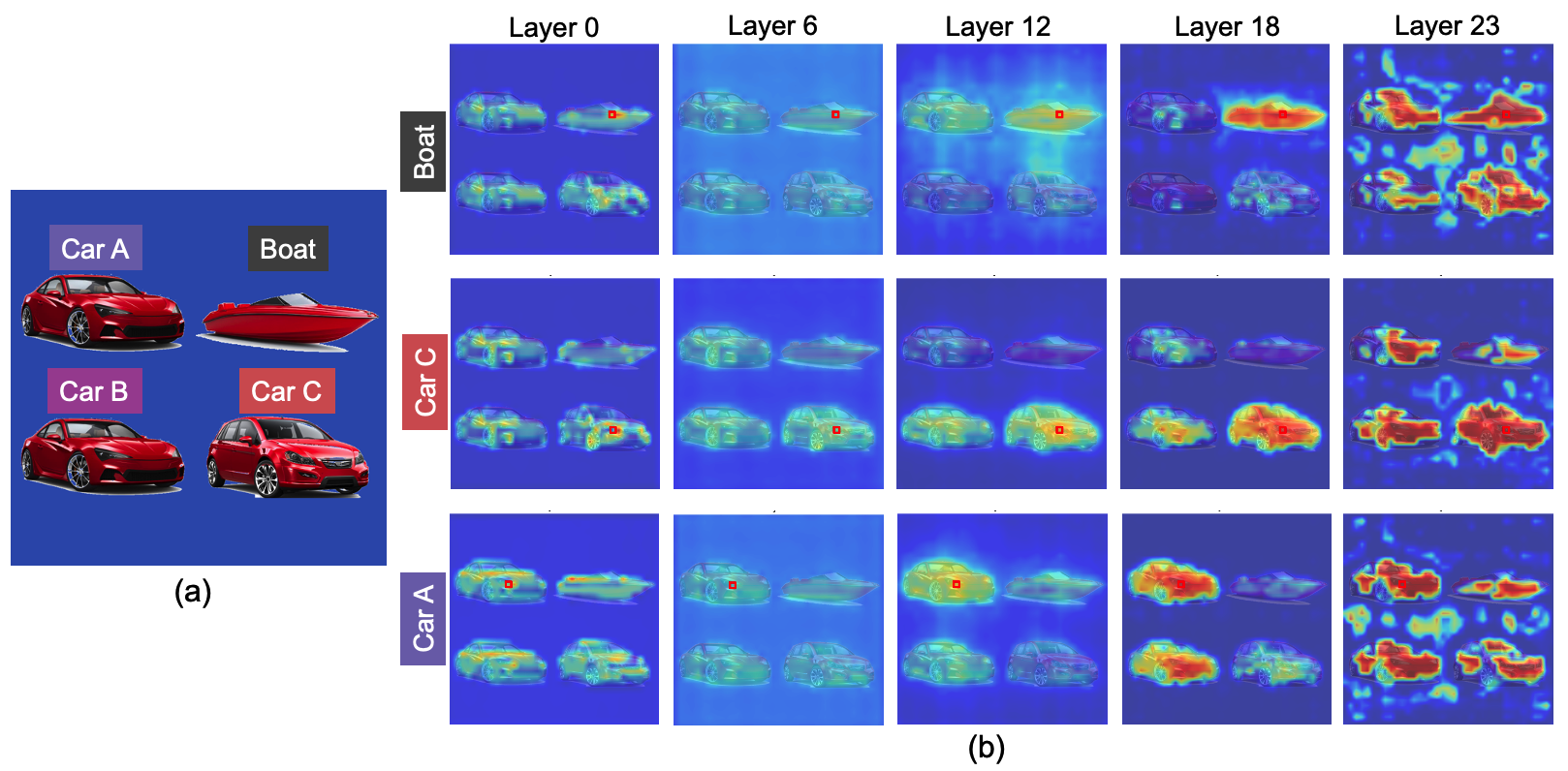
Figure: Layer-wise visualization of IsSameObject predictions on a hard test image with identical objects. Early layers attend to similar surface features (e.g., the red car or boat hull), mid-layers focus on local objects, and higher layers shift to grouping patches by object class.